前言
这是我第一次参加 CTF 竞赛,感觉还是很好玩的,也很有收获
由于本人是第一次参加CTF比赛,所以一开始不知道得到flag需要截图,所以有些题目没有flag截图,一些流程的图片也没有截到。但是我会尽量将思路讲清楚的
Writeup
MISC
broken.mp4
该题使用untrunc软件,以下载附件得到的第一个视频为reference file,以第二个视频为truncate file,生成第二个视频的修复视频,在视频的最后就可以获得flag

Sign in
该题通过在榜单寻找W4terDr0p队伍,即可获得flag

Priv Escape
通过sudo -l 可以发现,/usr/sbin/nginx对于当前用户,是被r00t赋权执行的,这就是本题的突破口。那么,解题的流程就应该是:通过r00t开启nginx服务,暴露一个端口,当前用户在访问这个端口的时候,可以通过该端口获取flag
具体流程:
直接开启nginx肯定是不可行的,关注到nginx的启动命令,可以通过-c 指定nginx.conf的路径。所以要先自己写一个nginx.conf,内容如下(只截取重要部分):
这里要指定pid的路径,a.pid是自己创建的,而且这个pid的值需要先通过sudo -u r00t /usr/sbin/nginx启动nginx,并用ps -ef | grep nginx 获取到(此处为120),再通过echo输入到a.pid


这些都要指定到可以访问的目录,否则会报错

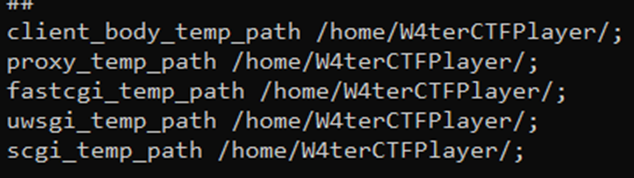
所有的include 也要注释掉,不然会报错


此处暴露18888端口供当前用户访问
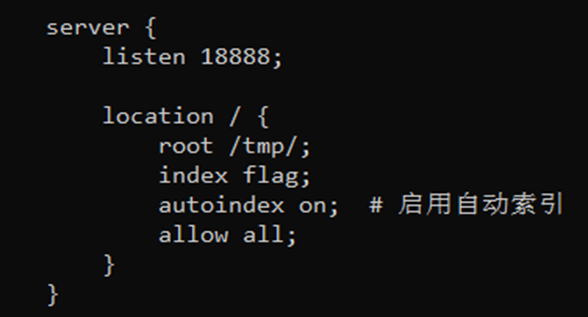
tips:所有的文件创建都可以通过touch + echo 的方式写入,如果写错了,就rm后重写
然后就可以通过sudo -u r00t /usr/sbin/nginx -c /home/W4terCTFPlayer/nginx.conf 开启nginx服务
tips:在此之前,要确定/home/W4terCTFPlayer下的所有文件可读,可以通过 chmod -R 777 /home/W4terCTFPlayer 实现
最后,就可以通过curl 127.0.0.1:18888 访问到flag啦

GZ GPT
一开始真的是一点头绪没有,只知道flag、CTF输入的时候会有不一样的回答,然后就一直卡在这。
然后后面有出现的这些“东西”,我真的有一大段时间认为是乱码!!!因为我用cmd的时候会有乱码出现,然后一直没有管(啊啊啊救命)
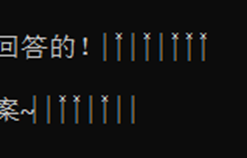
实际上认真观察之后可以发现,这里是有两种图案,而且有八个,所以就能联想到是八位二进制
那么我们可以验证一下,发现第一第二个二进制转ASCII 后就是W4,就可以确认是正确的解答方法了
然后不断发请求,会发现过了一轮有一句话是没有符号的,说明已经到结尾了。这时就可以将这些二进制数输入转换器,得到以下结果
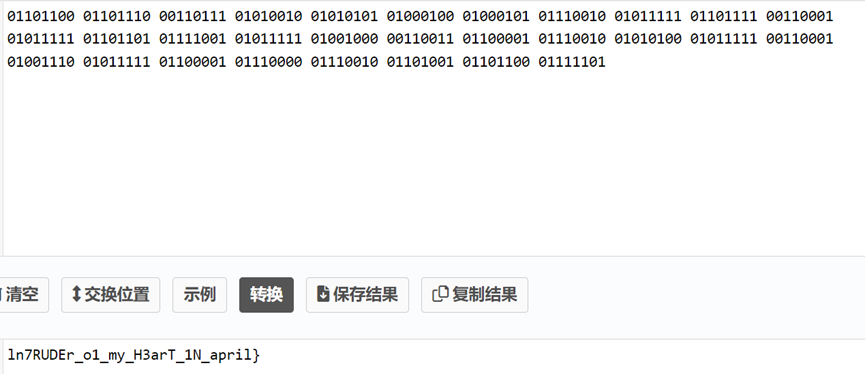
Spam 2024
首先拿到一个很长的垃圾邮件,很容易想到是Spam Encode生成的,Decode 后得到如下内容:
1 | 59,6f,75,20,6c,69,6b,65,20,65,6d,6f,6a,69,73,2c,20,64,6f,6e,27,74,20,79,6f,75,3f,0a,0a,01f643,01f4b5,01f33f,01f3a4,01f6aa,01f30f,01f40e,01f94b,01f6ab,01f606,2705,01f606,01f6b0,01f4c2,01f32a,263a,01f6e9,01f30f,01f4c2,01f579,01f993,01f405,01f375,01f388,01f600,01f504,01f6ab,01f3a4,01f993,2705,01f4ee,01f3a4,01f385,01f34e,01f643,01f309,01f383,01f34d,01f374,01f463,01f6b9,01f923,01f418,01f3f9,263a,01f463,01f4a7,01f463,01f993,01f33f,2328,01f32a,01f30f,01f643,01f375,2753,2602,01f309,01f606,01f3f9,01f375,01f4a7,01f385,01f449,01f30a,01f6b9,01f6aa,01f374,01f60e,01f383,01f32a,01f643,01f441,01f94b,01f451,01f4a7,01f418,01f3a4,01f94b,01f418,01f6e9,01f923,01f309,01f6e9,23e9,01f60d,2753,01f418,01f621,2600,01f60d,01f643,01f601,01f600,01f601,01f6ab,01f4c2,2705,2603,01f6ab,01f60e,01f52a,01f451,01f600,01f579,01f6ab,01f60d,01f32a,01f4c2,01f44c,01f34d,01f44c,01f993,01f590,01f923,01f60e,01f3ce,01f34d,01f3f9,01f34c,01f34d,01f3a4,2600,01f3f9,01f388,01f6b0,01f4a7,2600,2709,01f3f9,01f34d,01f993,01f385,01f374,2602,23e9,01f6aa,01f40d,263a,01f418,01f607,01f621,01f375,01f30f,01f993,01f375,01f6e9,01f4c2,01f44c,01f3f9,01f5d2,01f5d2,0a,0a,42,74,77,2c,20,74,68,65,20,6b,65,79,20,69,73,20,22,4b,45,59,22 |
可以看到,这里面包含了两种编码,一种是59形式 ,另一种是01f643 形式,第一种很容易看出是十六进制,所以放到 CyberChef 中解码得到如下内容:

根据提示,第二种形式的编码应该是 emoji 的 Unicode 编码,所以我写了一个小程序对其进行转换
1 | def unicode_to_emoji(input_string): |
得到内容如下:
1 | 🙃💵🌿🎤🚪🌏🐎🥋🚫😆✅😆🚰📂🌪☺🛩🌏📂🕹🦓🐅🍵🎈😀🔄🚫🎤🦓✅📮🎤🎅🍎🙃🌉🎃🍍🍴👣🚹🤣🐘🏹☺👣💧👣🦓🌿⌨🌪🌏🙃🍵❓☂🌉😆🏹🍵💧🎅👉🌊🚹🚪🍴😎🎃🌪🙃👁🥋👑💧🐘🎤🥋🐘🛩🤣🌉🛩⏩😍❓🐘😡☀😍🙃😁😀😁🚫📂✅☃🚫😎🔪👑😀🕹🚫😍🌪📂👌🍍👌🦓🖐🤣😎🏎🍍🏹🍌🍍🎤☀🏹🎈🚰💧☀✉🏹🍍🦓🎅🍴☂⏩🚪🐍☺🐘😇😡🍵🌏🦓🍵🛩📂👌🏹🗒🗒 |
这个编码也能比较容易看出,就是emoji-AES编码(emoji-AES编码的开头和结尾是有一定格式的)
那么关键就在于密钥,提示中说了密钥为KEY,但是解密一直在报错,奇怪了!密文大概率是没有错误的,也没有其他提示密文要做进一步变换,那么难道是密钥的问题吗?
这里出题人给我们挖了一个“小”坑,那就是 KEY 并不是密钥,🔑才是,因为 “I like emoji” 😂
解密成功得到如下内容:
1 | 0x???? ⊕ dxBUQVJndGJbbGByE3tGUW57VxV0bH9db3FSe2YFUndUexVUYWl/QW1FAW1/bW57EhQSEF0= |
这里的提示倒是蛮明显的,左边是一个4位16进制数,中间是异或,右边是类似于base64的编码。既然只是4位16进制,那么最大也就65536,完全可以爆破得出明文。
所以写个代码把所有可能结果输出,然后找就好啦
1 | import base64 |
得出明文如下:Key 2420: W4terCTF{H@V3_fuN_w1TH_yOUr_F!rSt_5pAM_eMa!I_IN_2024}
Pwn
Remember It 0
该题通过访问容器,连续答对10个string后,获得shell,ls发现目录中有flag,再用cat flag 命令得到flag
Web
GitZip
本题用到burp抓包,在routes.js文件中发现其中aget(‘/:htmlname’) 可以穿透攻击,将htmlname设为../就可以访问到父级目录,通过这个方法,在/tmp/flag前面不断加../,一层一层往上测试(在哪一层我忘记了,当时没有截图),用burp发送Get请求报文,就能在响应报文中找到flag了。
这里有个要注意的点是url必须通过编码再发送请求,否则无法找到flag。
PNG Server
首先用.txt写一个一句话木马,在文件头部加上GIF87a,这样就能识别为gif,可以成功上传
然后,注意到php.ini中有cgi.fix_pathinfo=1 这么一句话。
cgi.fix_pathinfo的解释如下:
该选项位于配置文件php.ini中,默认值为1,表示开启。当php遇到文件路径/test.png/x.php时,若/test.png/x.php不存在,则会去掉最后的/x.php,然后判断/test.png是否存在,若存在,则把/test.png当做文件/test.png/x.php解析,如若test.png还不存在如果在其前面还有后缀,继续前面的步骤,以此类推。若是关闭该选项,访问/test.jpg/x.php 只会返回找不到文件。
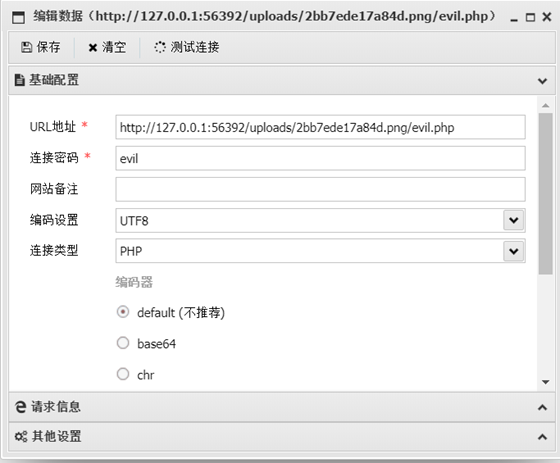
所以,上传图片后,用burp抓到响应报文,获取到图片的位置,再使用蚁剑连接,配置如下:
利用上面提到的性质,只需要在.png后面再添加 /任意名字.php,这样图片马就能被当成php执行了
连接成功后,回到父级目录,就能找到/flag
User Manager
该题在查看main.go的时候,发现在order_by字段作sql注入。
首先通过burp抓到一个正常的Get /users包,通过修改order_by= 后的字段,猜出名字的列名是Name和密码的列名是Secret,然后猜想数据表名叫users,经过测试发现没有问题。
然后将order_by= 后的字段改为以下语句Secret; INSERT INTO users (Name) SELECT Secret FROM users;
意思是将Secret列的内容全部覆盖Name列内容
经过编码后是Secret%3B%20INSERT%20INTO%20users%20(Name)%20SELECT%20Secret%20FROM%20users%3B
这样在响应报文中就会发现,Name字段中出现了flag
Auto Unserialize
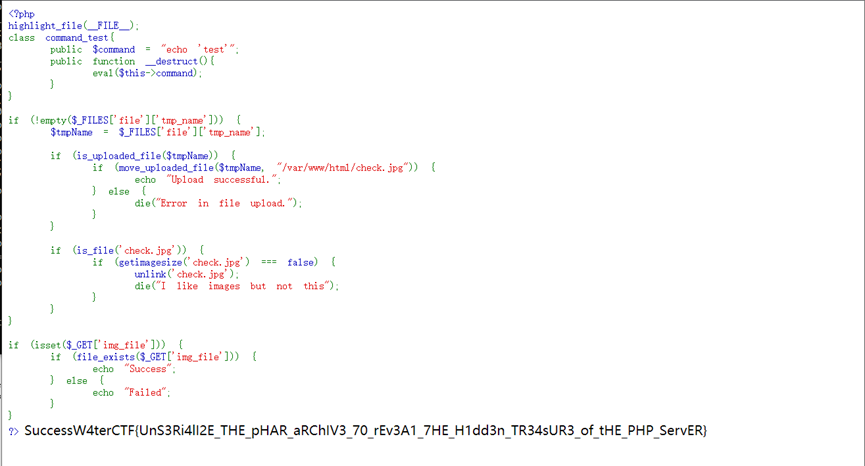
这是一个反序列化的题,在访问到的php代码中发现file_exist的参数是可以人为指定的
而且,对于文件的上传也没有很强的检测,只是判断是不是jpg
所以可以用 phar反序列化,构造一个 伪装成jpg的 .phar文件,代码如下:
1 |
|
执行后得到 .phar 文件,用curl 上传文件,发现上传成功
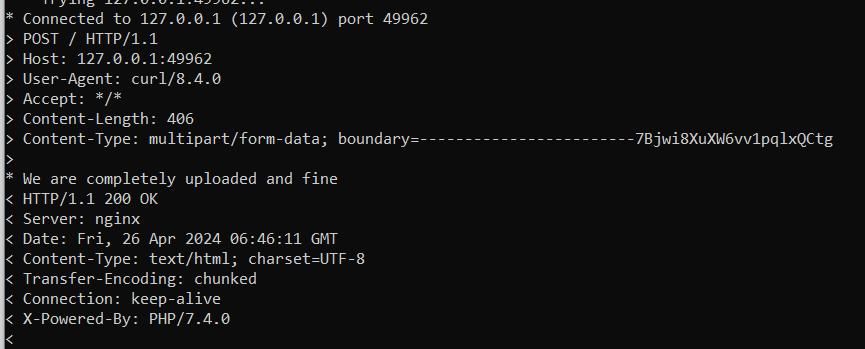
然后在网页地址栏输入以下url:http://127.0.0.1:49962/?img_file=phar://check.jpg
就能获取到flag了
Reverse
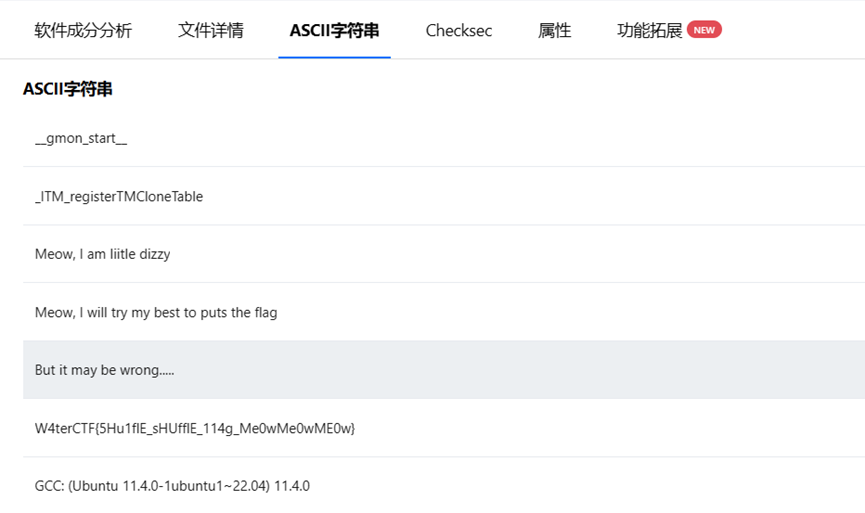
Shuffle Puts
使用BinaryAI,输入meow文件,在ASCII字符串中获取到flag
BruteforceMe
首先拿到一个elf文件,放到BinaryAI中,看一下这个文件相关的函数,以下是main函数
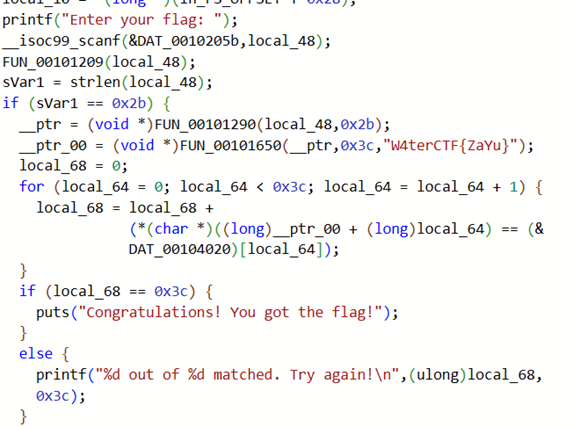
可以看到几个提示:
1、 flag的长度应该为0x2b,也就是43
2、 flag会被FUN_00101209函数处理,然后再被FUN_00101290 函数处理
3、 当输入的flag长度正确,即使内容不正确,也会有一个语句提示正确的位数
4、 查看这两个函数,都是对flag做一定的转换,主要是第二个函数,是一个base64编码的函数
知道了以上信息之后,就可以通过输出,开始猜这个flag是什么。
以下编写了一个脚本,实现的效果是,对 { } 内的值猜测
1 |
|
这个脚本是半自动的,每一次都需要自己修改start_position和input_string,在全都过一遍之后发现并没有全对,奇怪了!

其实是本身这个脚本有缺陷,在base64编码中,应该是每3个字符为一组,改成4个字符。而在这个脚本中,其实是每两个字符进行猜测,这样很有可能在某个位置猜错了,所以需要人工排错。
那应该怎样做呢?也是通过3个字符为一组这个性质,一个个组排查,比如:
先将UNr全部替换为某个一定不会在flag出现的符号,输入程序

发现正确的数量少了4个,说明这个组都是对的。
通过这样的方法一步步排查,最终发现是 N6Y 组和 n1m 组出现了问题,此时如何纠错呢?
因为每个组的长度为3,那么肯定前两个字符或者后两个字符,是用脚本被一起猜的,比如,在n1m 中,1m是被一起猜出来的。
那么现在我对n1这两个位置,用前面的脚本猜,就会发现n1变成了nu,相同的方法用于N6Y ,发现变成 _6Y
把新的flag提交到程序,发现终于对了

后记:其实在半自动脚本那里会有更简单的方法
1 |
|
但是这样得出的 flag 还是有问题的,需要人工排查Flag is: W4terCTF{UNr31AT3D_6Yt43_00NNb3N3n1m_RAt4d}
Crypto
Wish
这个题真的搞心态呀,放在密码题,但是并不是密码题做法呀
可以看到,这里是算抽奖概率的函数,如果“运气”足够好,那就能直接返回flag
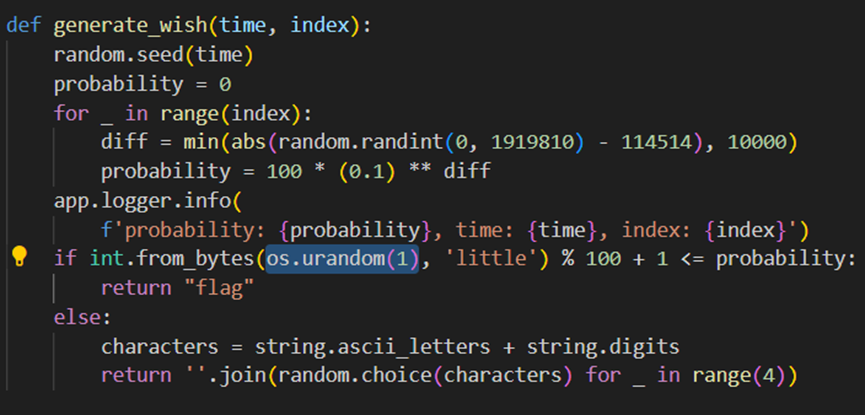
为什么要说是“运气”呢?仔细看第一行,random是设定seed的,也就是说,每一次抽奖,假如seed确定,结果也是确定的;而且index的值决定了for循环的次数
seed是由time决定的,time的范围可以从下面得到:

也就是0到86399
所以,写一个python代码,遍历0到86399的seed,看哪一个的算出 abs(random.randint(0, 1919810) - 114514)的值小于等于1,那么 probability的值就能大于10,代码如下:
1 | import random |
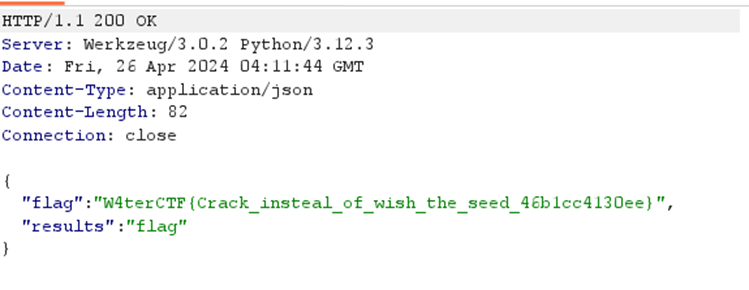
得出结果是seed为20544,abs(random.randint(0, 1919810) - 114514)的值为1
也就是说,有10%的概率可以抽到,开抽!
通过burp设定好报文格式,保证每次的time和index是一样的,格式如下:
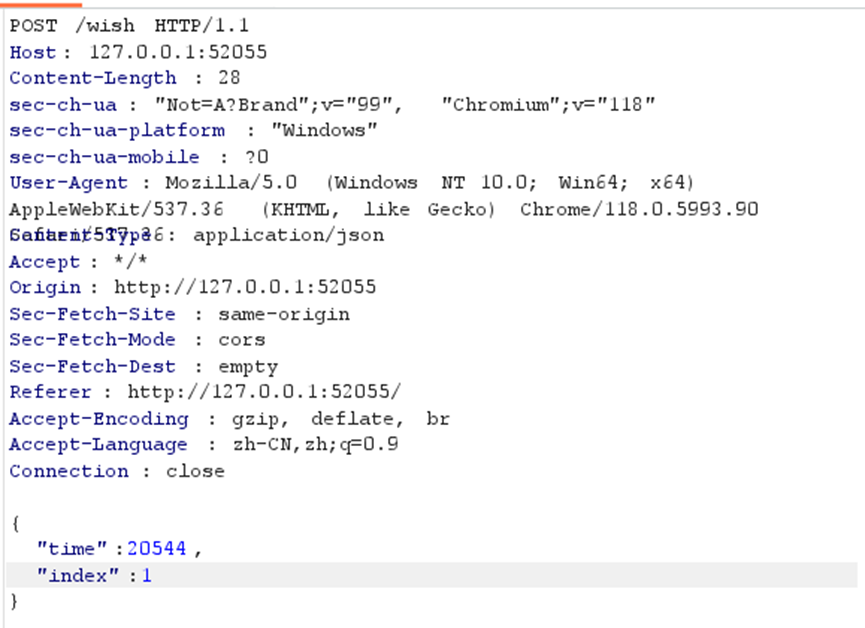
抽了n次之后,就发现flag了